ViT 精读
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
ViT | Dosovitskiy et al., 2020 | 【精读】
阅读重点
- 视觉 Transformer 的代表作,核心思想是将图像切分为固定大小的 patch,并视作序列输入 Transformer。
- 重点理解:patch embedding、位置编码、大规模预训练对视觉模型性能的影响。
- 这是很多后续 MLLM 视觉编码器的起点。
笔记
- ViT 主要采用有监督学习。因为 ViT 缺少 CNN 那种先天的视觉归纳偏置,比如局部性和平移等变性,它需要大量带标签数据来学出“哪些 patch 组合起来才是一个物体”。
- 这篇论文是 CV 和 NLP 架构统一的重要节点。ViT 证明:只要数据量够大,CV 不一定非要依赖卷积核,也可以直接用 Transformer 这套通用注意力机制。
- CNN 的卷积操作有权重、要训练,主要用于提取局部特征;池化操作通常无权重、不训练,主要用于压缩和筛选特征。这个流程天然带有图像局部结构假设,而 ViT 刻意把图像转成序列,让 Transformer 自己学习关系。
- Transformer 自注意力复杂度是 $O(n^2)$,直接作用在所有像素上序列太长。因此 ViT 把图片切成 16×16 patch,用牺牲部分细粒度像素关系的方式,让 Transformer 处理图像在算力上变得可行。
- 如果输入图片是 224×224,patch 是 16×16,那么图片会被切成 14×14=196 个 patch,再加上一个 [CLS] token,总长度就是 197。
- ViT 没有采用平均池化,而是使用 [CLS] token 聚合全局信息。它不代表任何具体 patch,只作为输出位置来代表整张图片做分类。
- 平移不变性指目标出现在图像不同位置时,最终分类结果仍然不变;更严格地说,CNN 前面层常体现的是平移等变性,即输入平移后特征图也相应平移。Transformer 如果没有位置编码,更像在处理一个集合,对空间位置并不敏感。
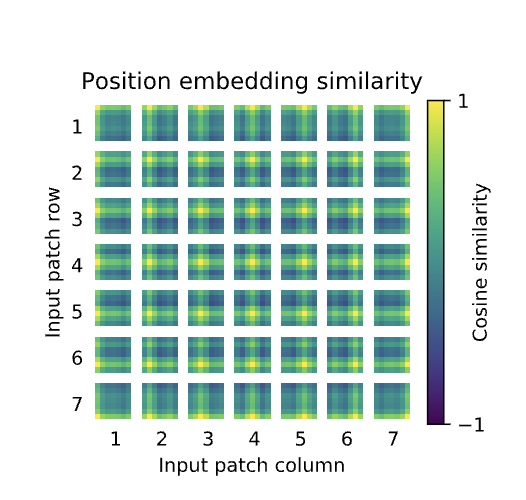
- ViT 使用一维位置编码,因为作者没有观察到二维位置编码带来明显提升。虽然图像是二维的,但 patch 被展平为一维序列输入 Transformer,一维位置编码也能学到二维空间结构。
- 微调时如果输入图片分辨率更高,patch 数量会增加,位置编码长度就不匹配。ViT 用插值(Interpolation)调整位置编码来适应新的输入尺寸,这种方法简单但实用。
- 位置嵌入可视化显示:一维位置编码也学习到了二维空间结构,说明模型训练过程中确实捕捉到了图像的空间关系。